Insights on AI, Data Science, Full Stack & Career
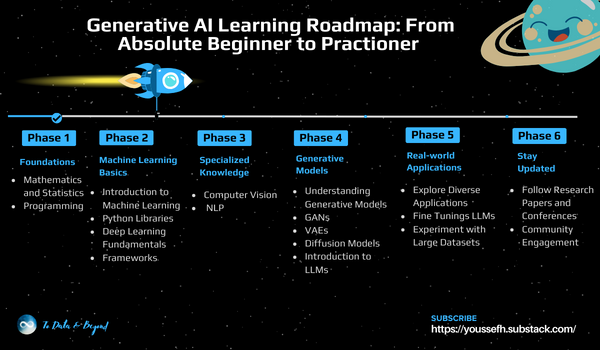
From Python basics to production RAG systems. Here is your 6-month roadmap to becoming a Generative …
Read More →
Data Engineering Roadmap 2026: From Beginner to Hired…
Read More →
FAST API is still hot in 2026. Here is the 6-month roadmap to go from zero experience to job-ready w…
Read More →